Fall Detection App: Cleaning Data and Extracting Features
Extracting features to differentiate falls among other activities
To create a fall detection app, we need data. As in a previous post, we measured 3260 activities with smartphones. Volunteers were falling on the ground, walking, sitting, and lying on a bed. However, we need to overcome some pitfalls.
Fall detection app: How I made people fall
People falling, sitting, walking, and laying down to create the dataset
Thresholds
Firstly, high acceleration peaks are in the measurements of the falls, which can be higher than 3g (g = 9.81 m/s2). The measurements with small amplitude overall are redundant for the research. The threshold has a value of 1.6g. The records, which do not contain a higher value, are ignored.
Secondly, Android phones do not have a constant sampling rate. The measurements, which contain a gap between two samples higher than 0.2 seconds, are ignored too.
Thirdly, if the peak occurred in the first or last second of the measurement, then the record is ignored too.
Result
After removing the measurements from the dataset by the rules. The dataset ended with 3129 measurements in total.
- 667 walks
- 840 falls
- 551 lays
- 1071 sits
Finding the region of interest (ROI)
Processing whole signals would be counterproductive. The aim is to create as efficient an algorithm as possible for smartphones, so we will limit ourselves to using only 1 second of the signal at max. The highest peak can be considered as the centre. The beginning of ROI starts with the first dip in acceleration. It contains values below 0.9g with a maximum length of 0.3s on the left side of the main peak. The end of the ROI is defined by the value of minimally 1.5g. The length of the right side is 0.7s at max.
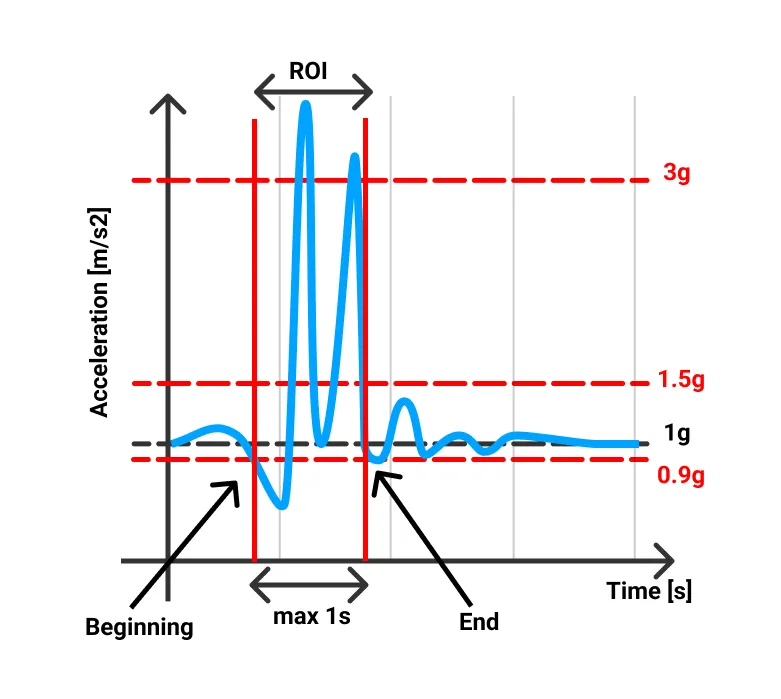
Image illustration of the ROI
Features:
I went through multiple resources and merged my ideas with other proposals during my search on this topic. I created the list of 19 statistical features calculated for the ROI. A lot of them are borrowed parameters from EEG and ECG research. Research resources are at the bottom of the post.
- average
- standard deviation
- variance / activity
- mobility, complexity — Hjorth coefficients
- average TKEO — envelope energy of the signal
- average output — average power of the signal
- entropy approximation — the amount of regularity in signal
- waveform length — an average of the first derivation
- Crest factor — max value/root mean square
- change in angle — change in angle from the X and Z axis of the acceleration
- change in angle with cosine — similar to change in angle, but it is taken from 1s before fall and 1s after fall (does not use the ROI)
- angle deviation — generalization of change in angle, which takes into account all axes
- free fall index — the value of acceleration during dip before impact
- min-max difference — the difference between the min value and max value
- 3g ratio — a ratio of samples above 3g : samples below 3g
- kurtosis — 4. standardized moment
- skewness — 3. standardized moment
- 1g cross rate — number of crosses through 1g threshold
Programmed parameters can be found here: Github link
Finding and filtering outliers
We can calculate features for all of the ROIs. However, the ranges of the values change with the calculated feature, so normalization is required. To save as much data as possible and avoid outliers, I developed a filter based on IQR rules.
IQR filtering
The IQR rules define the samples below 25 percentile and above 75 percentile — fences. For these samples, we search for the closest neighbours and calculate the average from these neighbours. The theory is: if the measurement is similar to others, even though it is considered an outlier, it is a valid value because there are other neighbours almost equal. In other words, a group of values cannot be ignored, because they are part of the data. If the value happens to be the outlier, it is averaged by the neighbours and the effect of the outlier is partially cancelled.
Without this move and with straightforward normalization, the models would loose even 4% and more of their accuracy.
After cleaning, the data are normalized as followed:
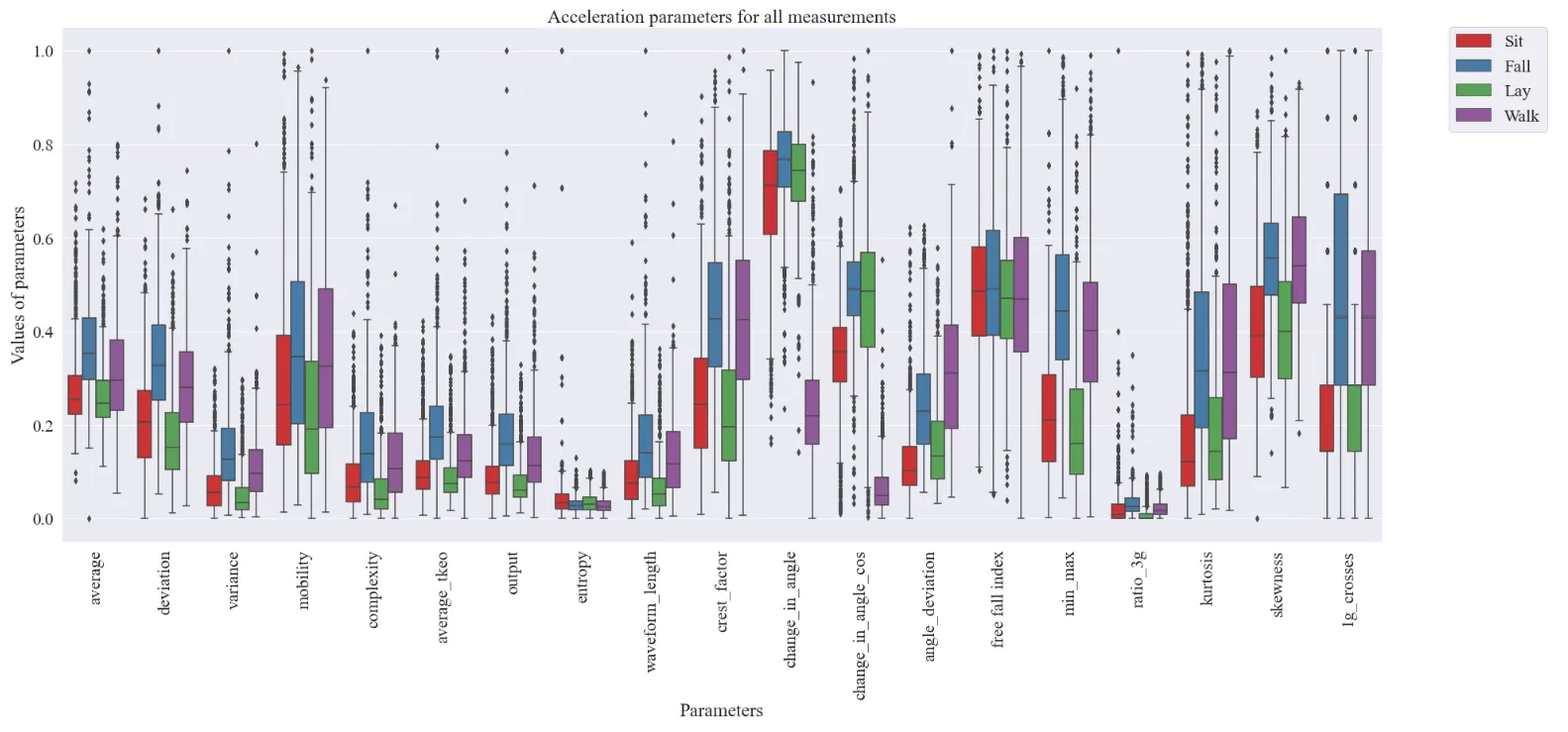
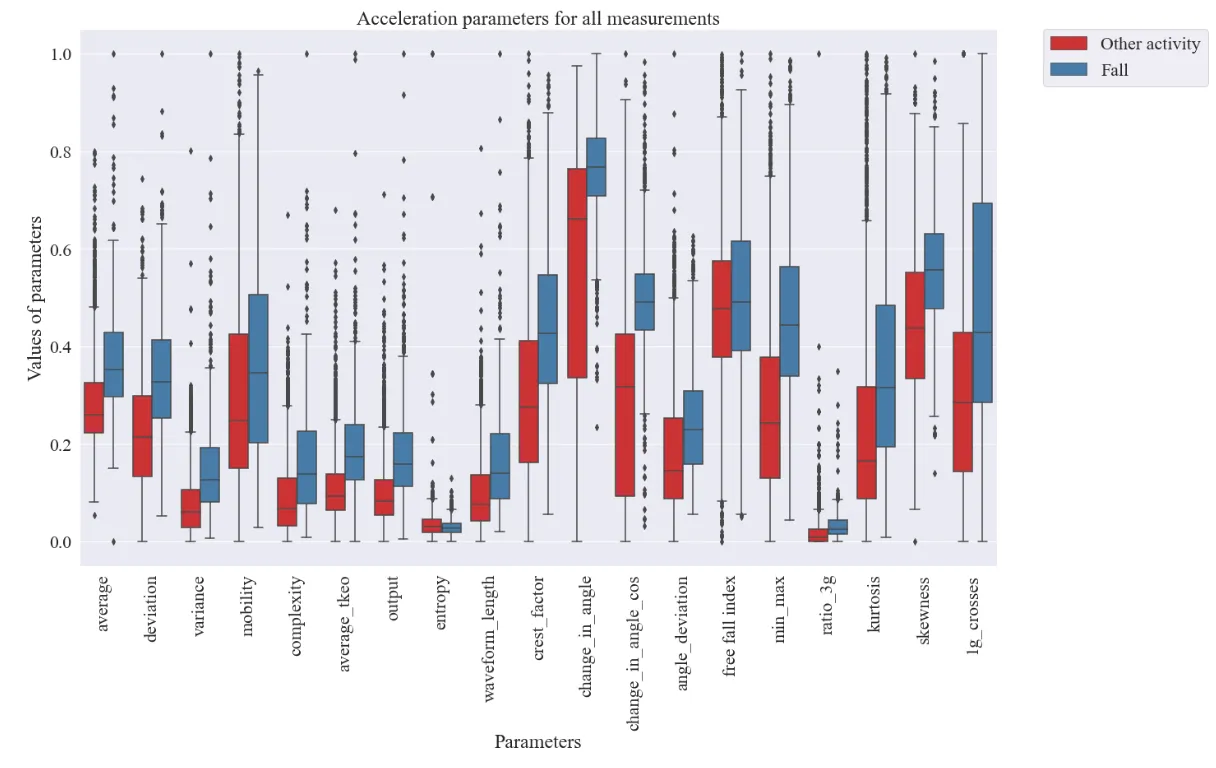
Normalized data categorized by activity type
Data interpretation
The target is to identify the features, which differentiate the fall from other activities. The charts show, that falling and walking are similar in parameters like simple average, crest factor, kurtosis and 1g crosses. The main difference comes between those two in a change in angle parameter. During the fall, the phone changes its position relative to the ground, so the angle of acceleration changes. During the walking, it is not happening. The same thing goes for the change in angle with cosine.
Most of the features have similar behaviour. They have higher values for the fall than for all other activities. It will be crucial to remove correlating features and redundant features like e.g. complexity or TKEO.
In the next part, we will try to predict the most important features and train SVM/Random forest models.
Resources:
-
authors: SANTOYO-RAMÓN, José Antonio, Eduardo CASILARI and José Manue CANO-GARCÍA
work: Analysis of a smartphone-based architecture with multiple mobility sensors for fall detection with supervised learning.
DOI: doi:10.3390/s18041155 -
authors: FIGUEIREDO, Isabel N., Carlos LEAL, Luís PINTO, Jason BOLITO a André LEMOS.
work: Exploring smartphone sensors for fall detection
DOI: doi:10.1186/s13678–016–0004–1 -
authors: ABBATE, Stefano, Marco AVVENUTI, Guglielmo COLA, Paolo CORSINI, Janet LIGHT a Alessio VECCHIO.
work: Recognition of false alarms in fall detection systems
DOI: doi:10.1109/CCNC.2011.5766464 -
author: HJORT, Bo
work: EEG Analysis Based On Time Domain Properties
DOI: doi:10.1016/0013–4694(70)90143–4 -
author: MARAGOS, P., J.F. KAISER a T.F. QUATIERI
work: On amplitude and frequency demodulation using energy operators
DOI: doi:10.1109/78.212729



